Wecr
Scrape the web for data recursively: text, videos, audio, images...
As a person who somehow ended up a data hoarder, it was only natural to write my own web spider to automate such a delicate task up to my needs. So here we have it.
Capabilities
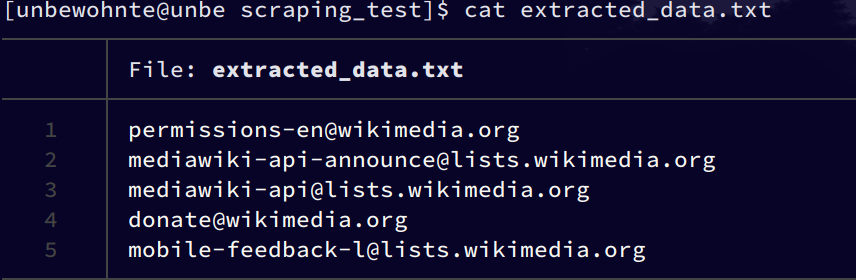
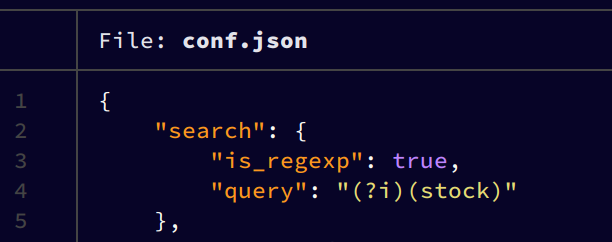
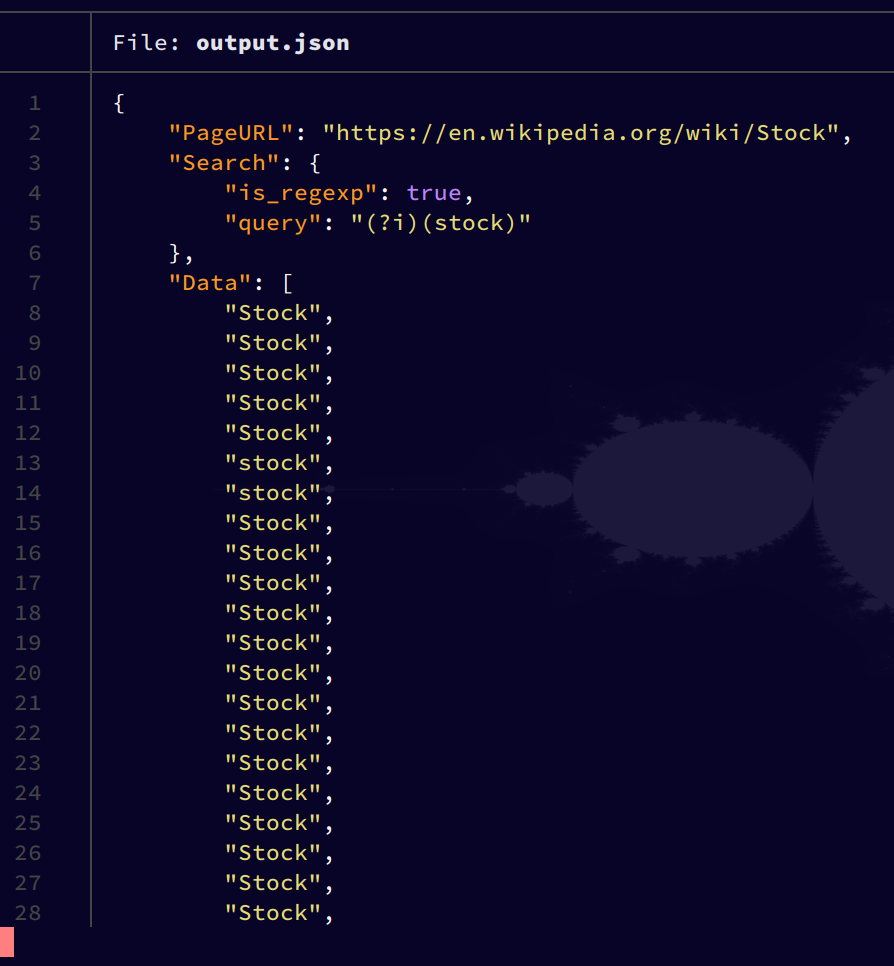
As of version 0.2.1:- Search for: text (static or via regular expressions, + email addresses preset), images, videos and audio
- Requests-control
- Save pages on which needed content has been found
- Blacklisting, whitelisting domains
- Depth of search
- Parallel worker amount
Documentation
For detailed instructions seeREADME.md on the project page.
Example
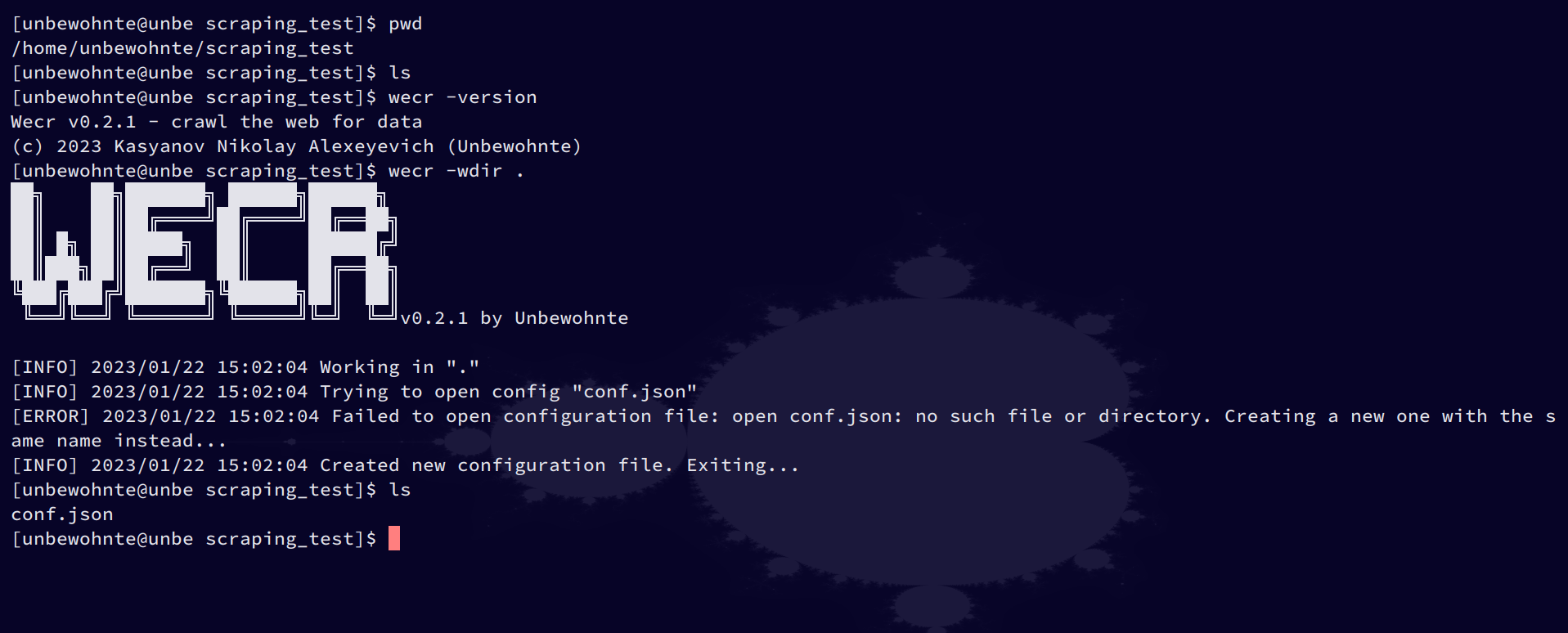
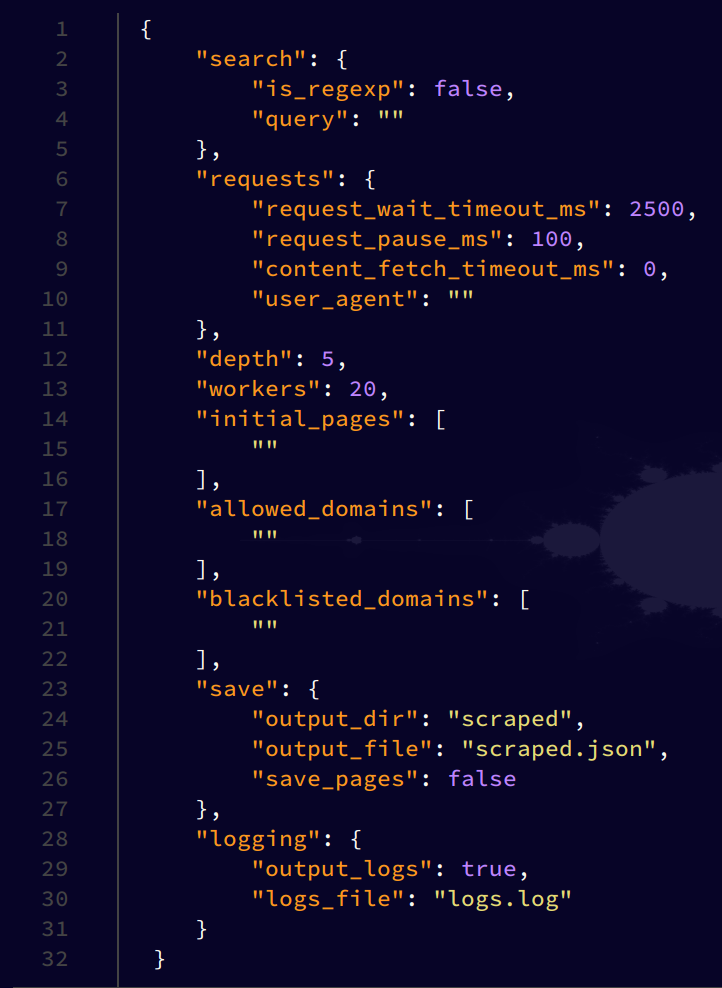
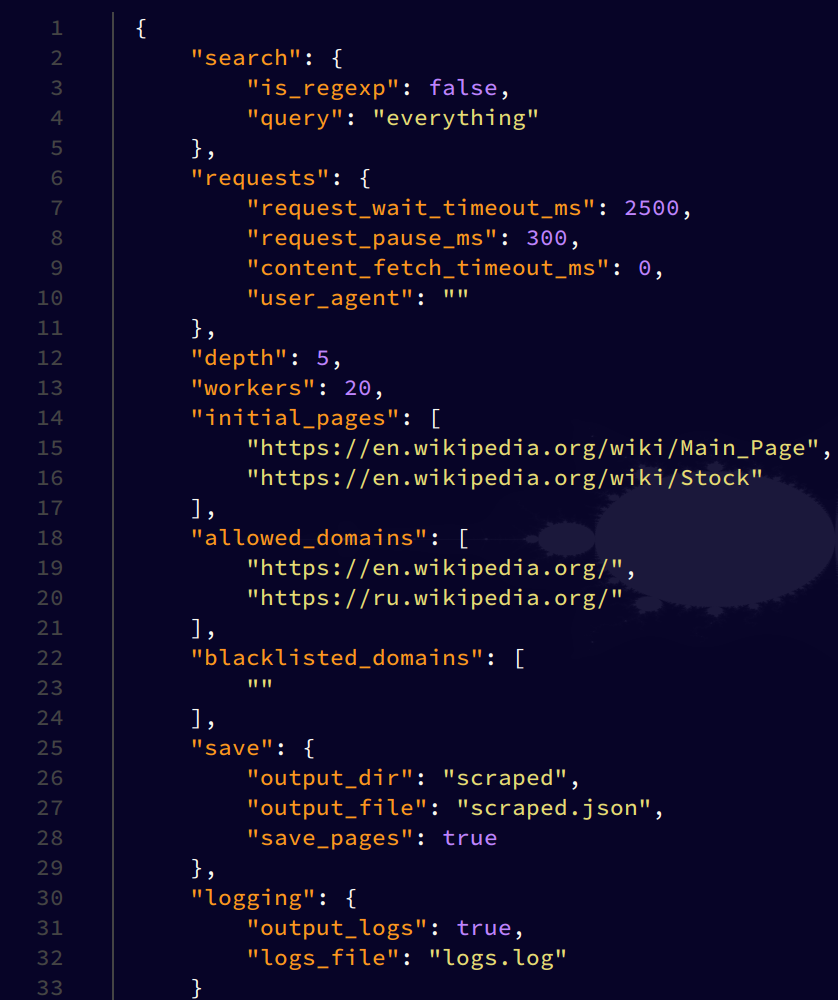
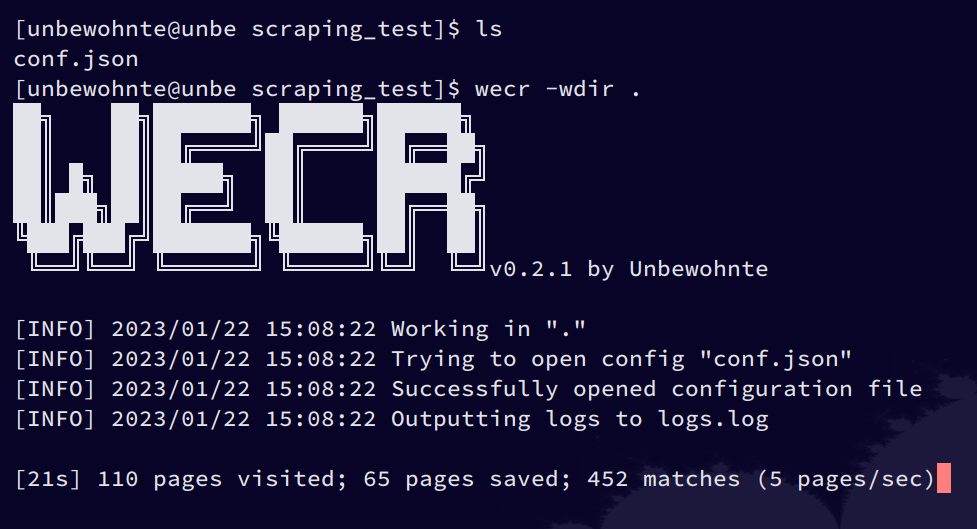

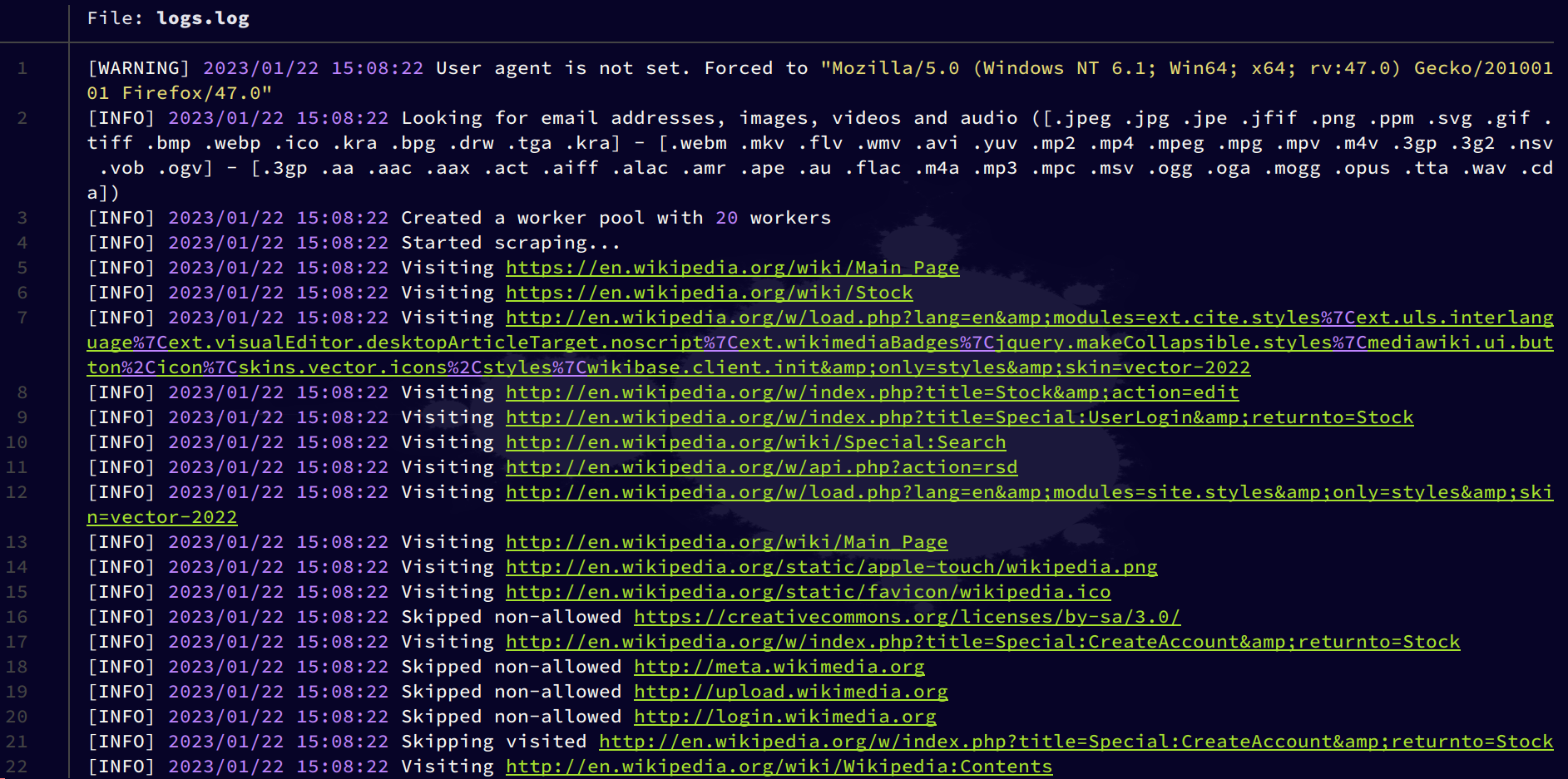
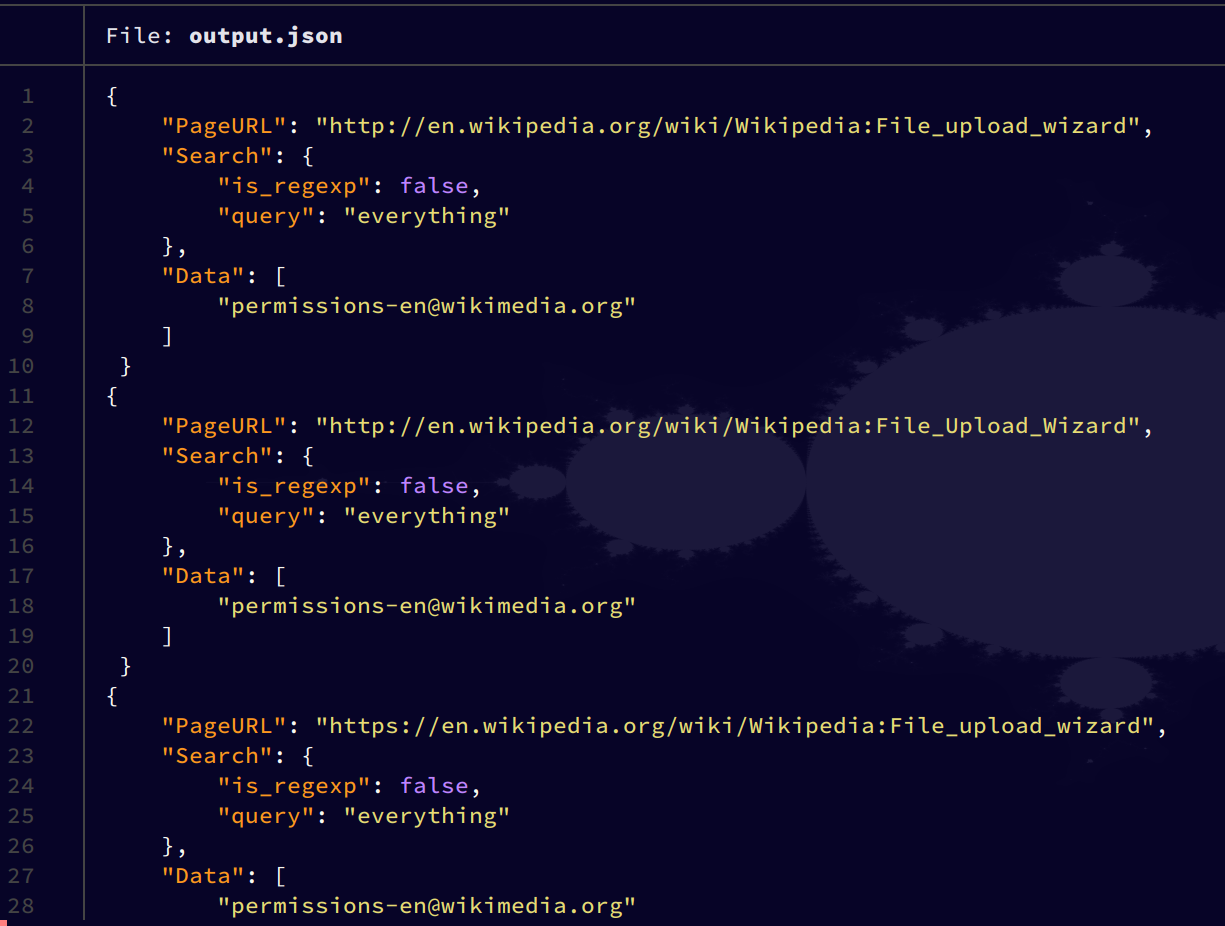
output.json
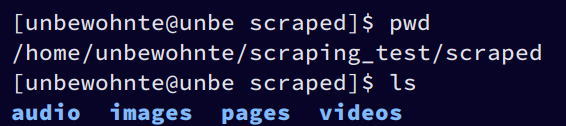
scraped
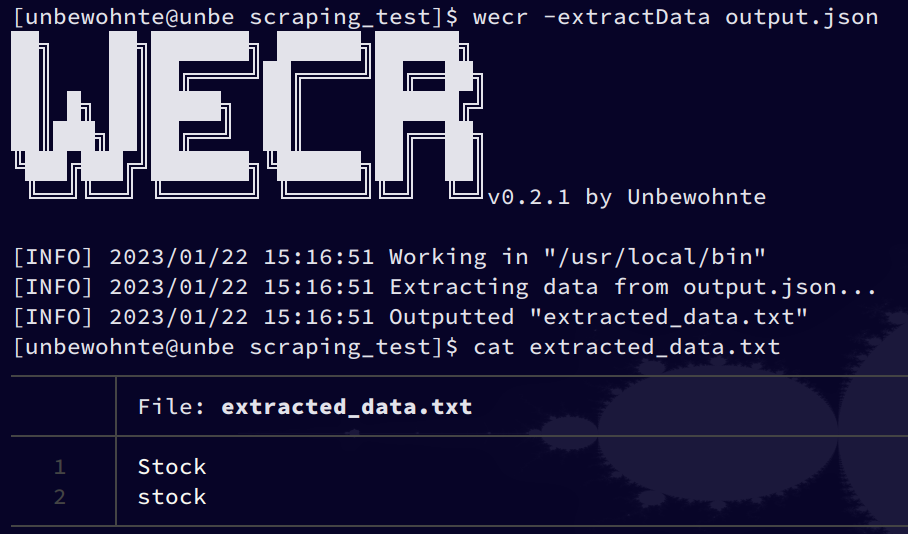
CTRL+C and now extracting the text data